近日,白翔教授团队与华为研究人员合作,推出了基于国产芯片的多模态文档大模型PDF-WuKong。

(PDF-WuKong模型的论文标题:PDF-WuKong:一个通过稀疏采样实现高效的长 PDF 阅读的多模态大模型)
PDF-WuKong不仅解决了现有多模态大模型难以处理长PDF文档的技术难题,其性能还超越了多个知名的国际闭源商业产品,展示了国产芯片在支持复杂大模型应用方面的实力。
长篇PDF文档的AI模型处理有多复杂?
长篇PDF文档包含文本、图表、公式等多模态内容,使得现有AI模型难以全面处理。目前主要有两种处理方法:纯语言模态和纯视觉模态。
纯语言模态将所有信息转为文本,可处理长文档但难以理解视觉元素;
纯视觉模态擅长处理图像和视觉布局,但计算成本高且难以捕捉页面间关系。
此外,现有文档问答数据集多局限于单页文档或单一证据问题,缺乏复杂多证据推理场景,难以有效评估模型处理长文档的能力。
这些限制阻碍了AI模型在处理复杂多页PDF文档时的表现。
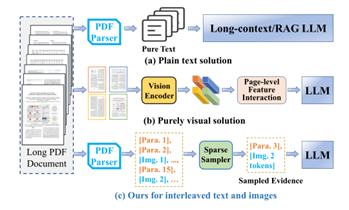
(传统AI模型对长篇PDF的处理方案图例)
如何打破多页PDF处理对AI模型的限制?
1、PDF-WuKong模型
针对这一问题,论文提出了PDF-WuKong模型。该模型旨在实现长篇PDF文档的多模态理解,克服现有模型仅将PDF视为单一模态的局限性。
其核心结构包括:
1)文档解析:将PDF文档解析成符合人类阅读顺序、包含文本块和图像块的结构化内容。
2)稀疏采样:通过计算用户查询与文档各部分的相似度,从缓存的嵌入中选择与查询最相关的文本段落和图像块,并传递给后续的模型部分。
3)答案生成:将筛选出的关键信息联合问题和指令送入大模型,并且生成准确的答案。
PDF-WuKong通过端到端方式优化稀疏采样器和大语言模型,不仅提高了长文档的处理效率,还提升了模型的解释性。
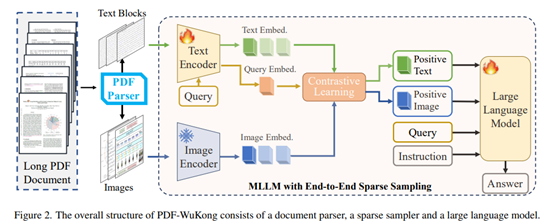
(PDF-WuKong方法的核心结构图解)
2、PaperPDF数据集方法
为了克服现有数据集局限于单页文档或单一证据问题的缺陷,论文还提出了一种高质量问答对生成方法,并据此构建了PaperPDF数据集。
该方法包括四个主要步骤:
1)文档解析:使用Grobid工具解析约89,000篇arXiv论文,将其拆分为多个文本块(如段落)和图像块(如图表)。
2)规则抽取:使用预定义的规则随机选择部分解析出的文本块和图像块。
3)指令构建:根据不同类型问答数据相应的提示模板构建生成提示送入现有的多模态大模型产品(如Gemini、GPT4v)产生相应的问题和答案。
4)数据过滤:应用自动化规则过滤训练集,人工检查测试集。
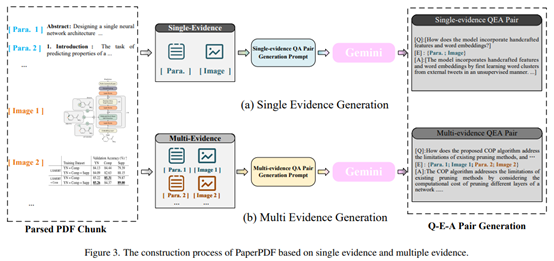
(PaperPDF数据集方法的主要步骤图解)
PDF-WuKong模型的推出有什么意义吗?
PDF-WuKong是首个基于国产化芯片的多模态长文档大模型,开创性地为输入窗口长度受限的多模态大模型理解和处理包含大量文本和图像信息的长篇PDF文档提供了高效解决方案。
此外,文章还提出了一套高质量的长文档问答对的生成方法,并开源了相应的数据集PaperPDF,为后续在长文档理解和多模态检索领域的研究和应用探索提供了有力的支持。







